Sysepub: Symmetric semi public key algorithm!
Introduction Encryption Decryption Plaintext attack KPBFA algorithm Bug List
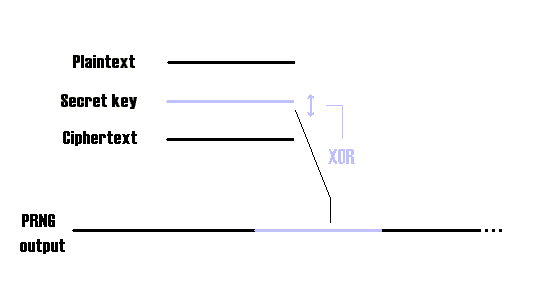
One time pads (o.t.p) with random key are known to be perfect cryptographical systems. Using a
pseudo-random key is more practical, but not perfect anymore.
So these apparently very good system have at least 3 big weaknesses or limitations:
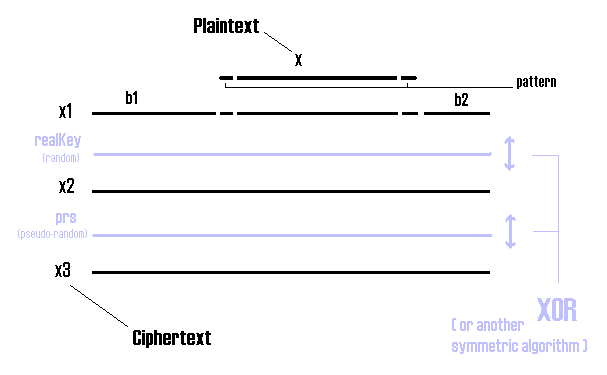
I guess the following notations are obvious:
Sysepub algorithm (decryption)
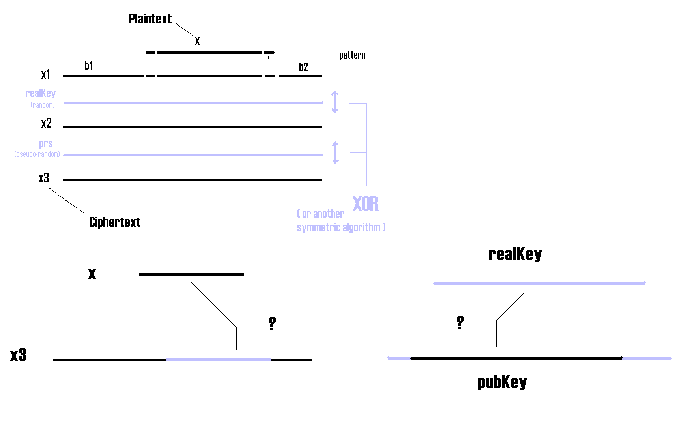
The plaintext attack : this is the critical point, where I conjecture that this system is immune to.
First of all let's see how it can be successfully made in the simple case of pseudo-random o.t.p.
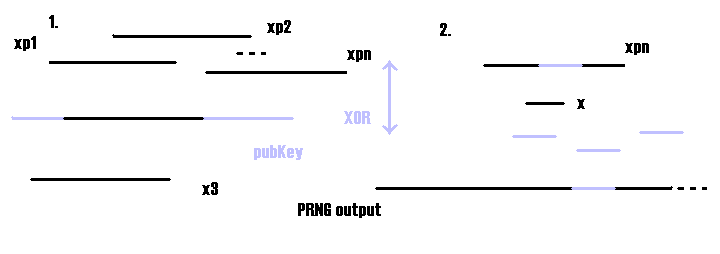
I wrote, using pseudo-code, an algorithm to try the plaintext attack: its (ugly) name is KPBFA (Known Plaintext Brute Force Attack). Sysepub challenge example. Let's call t the time needed to perform the steps from 2.3.1 to 2.3.4. In the challenge the plaintext is of 56 KB, the ciphertext of 194 KB and the pubKey of 200 KB. So there are nearly 6000 possible xps, and for each of them, if he is unlucky, C must try nearly 138000 subsets of the length of x. In other words d1~6000, d2~138000 Then the computational time is nearly d1*d2*t~6,000*138,000*t = 828,000,000*t in the worst case.
Bug List
this form .
Teutoburgo Home
Sysepub index
Download Sysepub for free!
Copyright Pierre Blanc 2002